AI pioneer and educator Andrew Ng gave a compelling talk at Sequoia’s AI Ascent 2024 a couple of weeks ago. I took some notes and have provided a few thoughts of my own. Presentation highlights are presented at the top, and a fuller synopsis with Ng’s citations is provided at the bottom.
Ng’s presentation offers a compelling analysis and argument for advancing research and development in AI agents. His categorization of agent behaviors provides clarity, countering vague claims about “AI agents.” In a field evolving as quickly as AI, these categories are invaluable for tracking progress and evaluating results.
Ng used AI code generation to showcase the power of agentic patterns, highlighting how planning, tool use (e.g., testing and running code), and reflection (e.g., AI-led code reviews) surpass zero-shot prompting. Code generation is especially suited for demonstrating these methodologies because of its objective benchmarks and studies showing how smaller models in agentic workflows outperform naive approaches with larger models.
Cited code-generation agents include:
But how representative is code generation of other tasks? Code is unique in being quasi-multimodal – text that functions beyond reading. Its execution and validation by interpreters make it an excellent test case, but these characteristics may not apply to many other tasks. However, programming’s unlimited complexity (“build me Google”) and objective evaluation make it an ideal area to showcase agentic methodologies.
For non-coding tasks, Ng cited eight papers, two for each agentic behavior, showing significant improvements over zero-shot approaches. Tasks involving structured, step-wise reasoning or large-scale information analysis intuitively benefit from – or even require – agentic workflows. For example, synthesizing conclusions from hundreds of documents exceeds current context window sizes, even as they expand, and benefits from guided agentic strategies.
Ng doesn’t delve into another important advantage of agentic behaviors: the paper trail they produce. When agents collaborate and use tools, they generate intermediate records that provide:
These intermediate outputs also create opportunities for future applications. Together, these features make agent collaboration an exciting frontier in AI development.
Today, most of us interact with large language models (LLMs) using a non-agentic workflow. This involves typing a prompt and generating an answer, akin to asking a person to write an essay without ever using the backspace key. Despite the inherent challenges, LLMs perform remarkably well in this setup.
In contrast, an agentic workflow is more iterative, and thus more similar to how humans work. For instance, an AI could first generate an essay outline, determine if it needs to conduct web research, write a draft, review its own draft, and revise accordingly. This iterative approach enables the model to think through its tasks and refine its output, often delivering far better results.
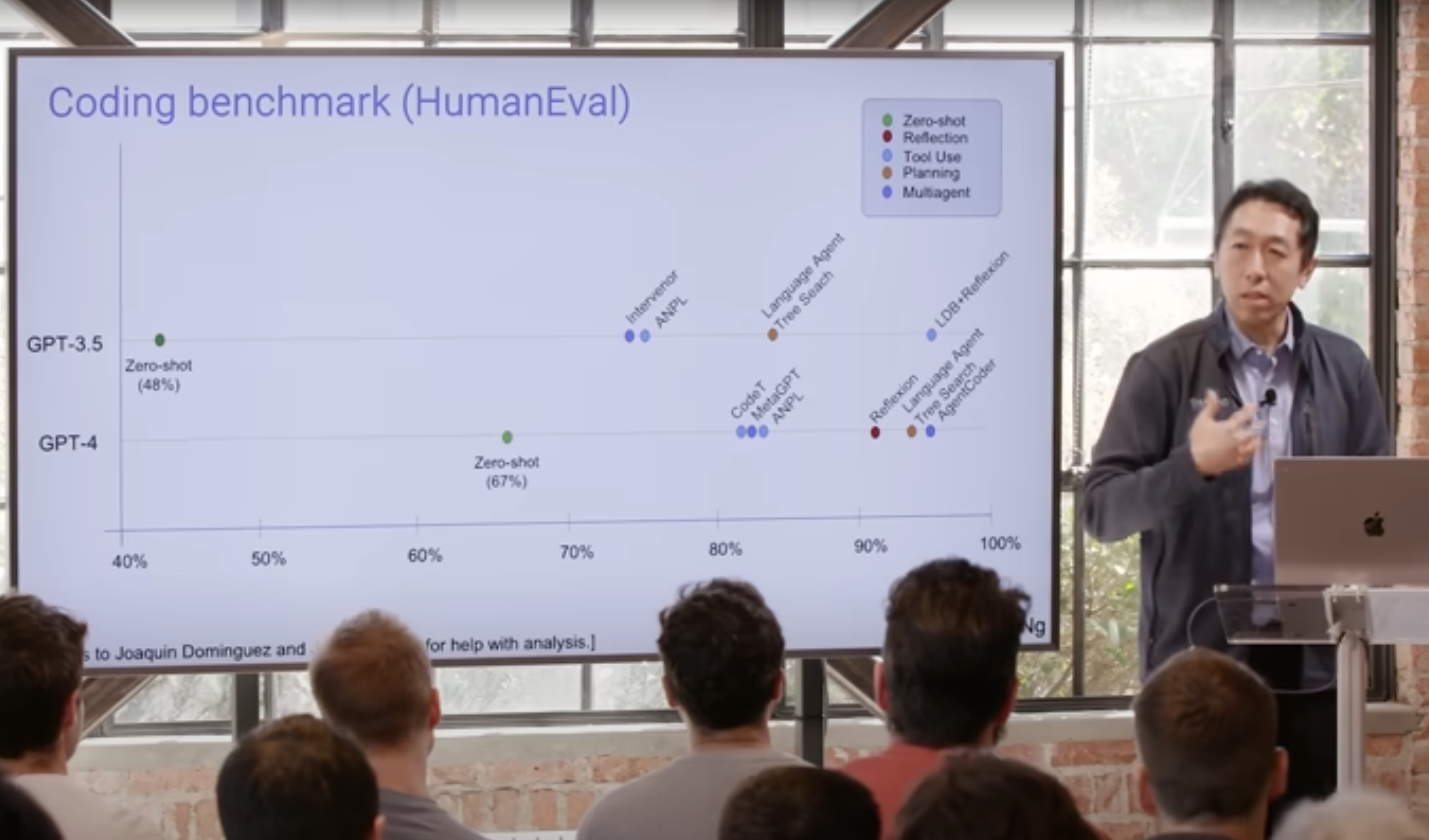
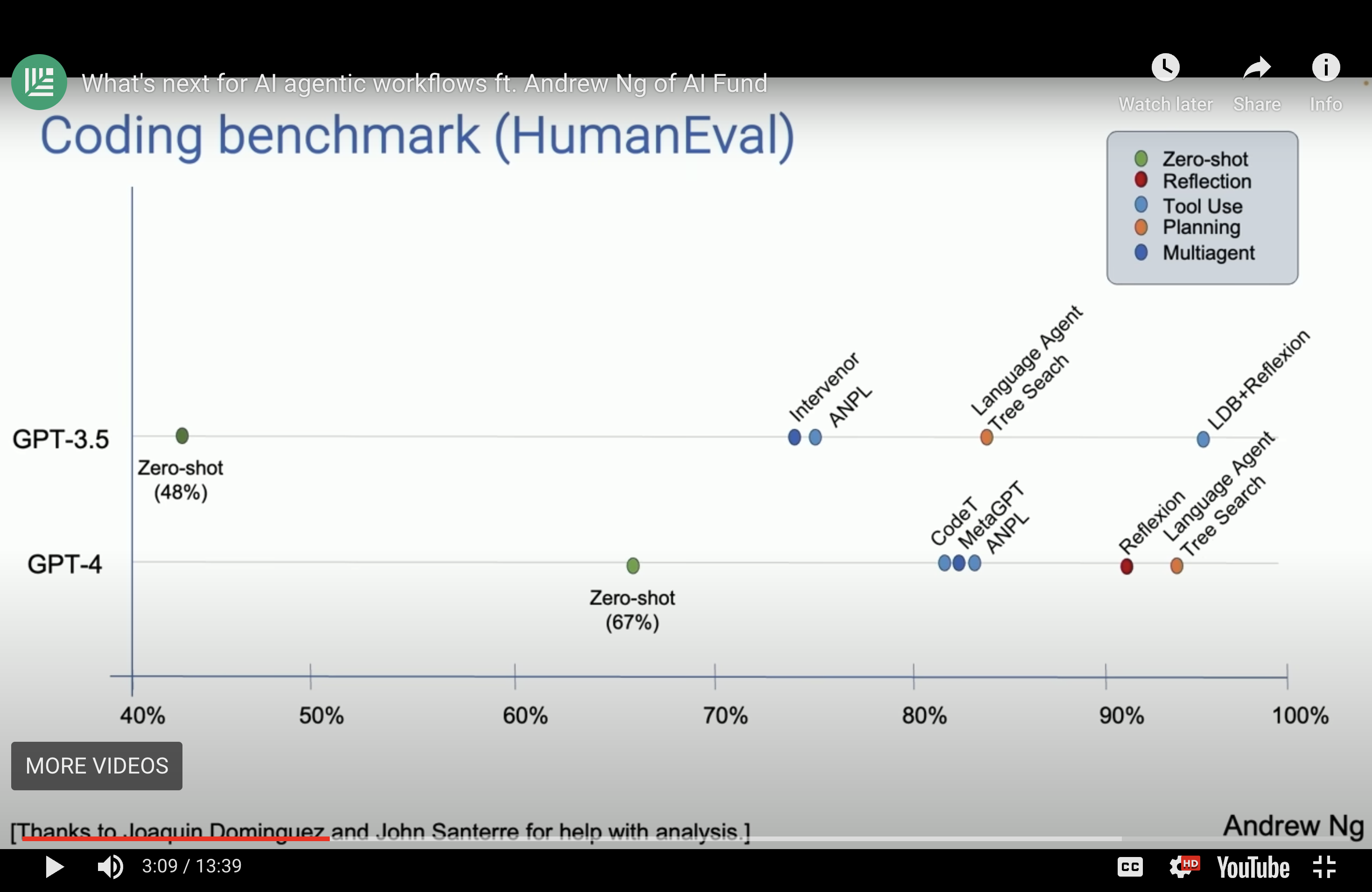
In his own work, Ng has been surprised by how effective these agentic workflows can be. His team analyzed the performance of these workflows using the “HumanEval Benchmark” for coding tasks, originally released by OpenAI. This includes challenges like: “Given a non-empty list of integers, return the sum of all elements at even positions.”
With zero-shot prompting, GPT-3.5 solved 48% of the tasks correctly, while GPT-4 performed better, solving 67%. However, when GPT-3.5 was used with an agentic workflow, its performance surpassed GPT-4 in a zero-shot context. Wrapping an agentic process around GPT-4 improved results even further. This highlights the potential for agentic workflows to enhance performance across various applications.
The term “AI agents” is widely used, often in vague or aspirational contexts. Ng wants to concretize this concept by categorizing the broad design patterns emerging in the space. While the field is chaotic, with abundant research and open-source contributions, Ng identifies four main patterns:
Agentic workflows are transforming how we use LLMs. For example, multi-agent collaboration can include scenarios where different models debate or critique one another, leading to better results. Tools like GPT-4 and Gemini are increasingly capable of supporting these workflows, though there is room for improvement in reliability.
One challenge with agentic workflows is user patience. Unlike traditional web searches, which provide near-instant results, agentic tasks may require minutes or even hours to complete. Learning to delegate tasks to AI and waiting for thoughtful results is a shift we’ll need to embrace. Fast token generation also becomes critical, as it allows iterative workflows to proceed efficiently.
Looking ahead, Ng expects agentic reasoning and design patterns to expand dramatically this year. While advanced models like GPT-5 or Gemini 2.0 promise enhanced zero-shot capabilities, integrating agentic workflows into current models can yield comparable performance in many applications. This shift represents a step forward on the long journey toward Artificial General Intelligence (AGI).